
Shared Canvas: Dealing with Uncertainty in Digital Facsimiles
Robert Sanderson
Los Alamos National Laboratory
rsanderson@lanl.gov
The Shared Canvas data model provides a solution for many of the challenging use cases in representing medieval manuscripts in a digital form. Through its use of distributed information, building upon the best practices of the Linked Data community, Shared Canvas allows multiple institutions and individuals to independently contribute to the descriptions, digitization, transcription and commentary regarding a manuscript. This allows for dispersed fragments to be virtually rebound, multiple pathways and sequences through a manuscript, leaves to be represented even if they have not been digitized, and many more.
The data model is one outcome of the Digital Manuscript Technical Council, initiated by Stanford University and including partners such as the British Library, Bibliotheque Nationale de France, UK National Archives, e-codices, Oxford, Harvard and Yale Universities, and Los Alamos National Laboratory. It re-uses existing ontologies and tools such as the OAI-ORE model for aggregating resources and the Open Annotation ontology for creating associations between resources, both for generating the facsimile and scholarly discussion about it. As more institutions adopt the model, it will facilitate seamless interfaces that allow the reuse of tools and viewing environments for scholars to perform cross-repository research from their desktop.
This paper will, after introducing the data model, focus on the how Shared Canvas can represent the uncertainties that occur when trying to accurately reproduce a physical, text bearing object such as a medieval manuscript, and demonstrate at least three different implementations.
Towards a Social Semantic Scholarly Graph: the ‘Wittgenstein Incubator’ as part of an attempt to further model scholarly discoursive interaction in DM2E
Stefan Gradmann
KU Leuven
Stefan.Gradmann@kuleuven.be
The DM2E project (http//:dm2e.eu) includes an attempt to formally model scholarly discoursive interaction built on an extension of what started with John Unsworth’s ‘Scholarly Primitives’ proposal back in 2000. This is further extended into a more generalized formal model of the scholarly research domain and of the primitive building blocks (such as augmentation, comparing, modeling etc.) which would then in turn be formalized to some extent in proposals for basic ontologies enabling to established typed relations between corpus elements and contextual data in the form of semantic annotations. In a first attempt to put this approach to work a site is currently being set up which contains the digitized manuscript of Wittgenstein’s Brown Book together with transcriptions and related research literature enabling a small group of 10 specialists to build a system of RDF-Statements pertaining to this resource set over the coming 6 months and which would result in a social semantic scholarly graph which might yield new hypotheses concerning Wittgenstein’s work as well as being a potential corpus of meta-research itself. Needless to say that at least some of the output will be less significant, if not nonsensical: the approach has some inbuilt modesty. I will try to present some of the general ideas behind this environment as well as the Pundit tool we are using for putting this to work and will try to give an idea of the look and feel of the ‘incubator’.
A digital work environment for the transcription, editing and publication of manuscripts
Stefan Dumont
Berlin-Brandenburgische Akademie der Wissenschaften
dumont@bbaw.de
Martin Fechner
Berlin-Brandenburgische Akademie der Wissenschaften
fechner@bbaw.de
Manuscripts from various eras can both differ as well as share text characteristics, such as their text structure. These differences arise not due to transitions from one era to another, but due to the author’s intended purpose for the text. Thus, a court protocol from the 15th century and a city council protocol from the 19th century can be much more similar than as they appear at first glance. In both cases, decisions deemed relevant are recorded, chronologically sorted, and supplemented with marginalia. Of course, differences are found in the details of these two manuscripts, however in regard to the question which technological solution is most suitable for the transcription and publication of an edition of such texts, these details remain negligible. Crucial is not the era in which the source was created, but the text structure and the aim of the research.
The Berlin Brandenburg Academy of Sciences and Humanities is home to numerous research projects with diverse subject matter, whose sources originate from multiple epochs. The TELOTA research group consults and offers support for the digital aspects of these projects. TELOTA is regularly confronted with the challenge of developing technical solutions for the transcription and editing of sources from different epochs. With this in mind, a solution was developed in the last year for editing manuscripts, consisting of various software compo- nents (such as Oxygen XML Author, existdb, and ConTeXt). It allows researchers to construct and edit transcriptions in TEI-conform XML, to add apparatuses, and provides a publication tool.
The researcher does not view the XML code directly, but instead works with an intuitively operable graphic user interface, including toolbars, buttons, and dialog menus. Knowledge of XML is unnecessary for its use. The editor can designate through simple actions not only the text structure, but also the typical phenomena found in a manuscript. The editor can mark deletions, additions, illegible text, etc. Passages or words in the document can be linked to a separate register (for example for persons or places). The entry interface is supplemented with a website that is generated through the database, as well as an automatic PDF, which provides the text in the format as it is found in the printed edition.
A prototype of this work environment has been created for the academy project “Schleiermacher in Berlin 1808-1834”, in which three different kinds of manuscript types from the 19th century are edited: letters, lectures, and a daily calendar. Despite their differences, these three manuscript types are edited with this same interface. The work environment has been in productive daily use by the research staff of the Schleiermacher project for the last year. This year it will be implemented for additional academy projects from different epochs. The TEI-XML-Schema, which serves as the basis for the interface, can be customized to the manuscript type or exchanged with a new schema. It is thus possible to implement this work environment for medieval sources, such as charters, urbarium, or account books.
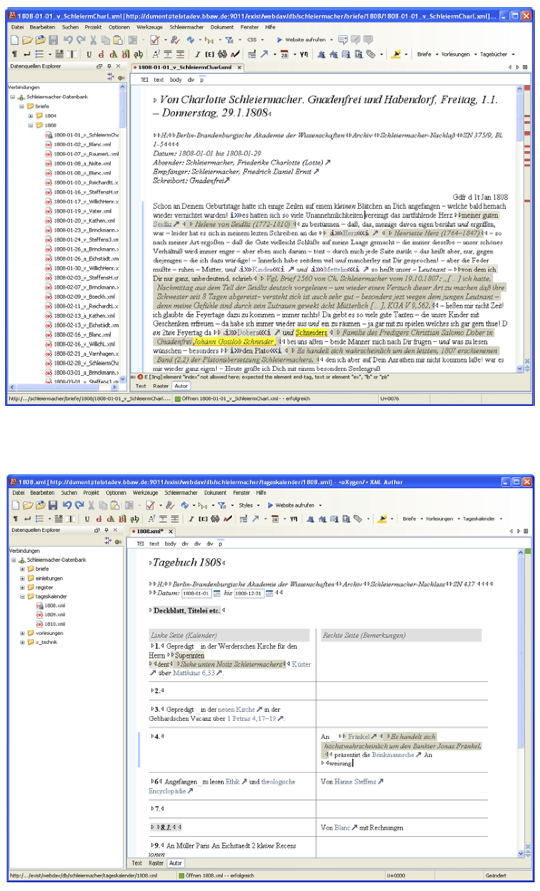
fig. 1: screenshots
Dumont, Stefan; Fechner, Martin: Digitale Arbeitsumgebung für das Editionsvorhaben »Schleiermacher in Berlin 1808–1834«. In: digiversity – Webmagazin für Informationstechnologie in den Geisteswissenschaften. URL http://digiversity.net/2012/digitale-arbeitsumgebung-fur-das-editionsvorhaben-schleiermacher-in-berlin-1808-1834/ [14.02.2013]
Els Stronks (Utrecht University, NL)
Annotated Books Online
Els Stronks
Utrecht University
E.Stronks@uu.nl
Annotated Books Online (ABO) is a digital platform for the study of the history of early modern reading. In the early modern period, readers were used to writing their thoughts and remarks on the margins of their books; an activity that is now frowned upon by most librarians and book collectors. Such annotations can however tell us a lot about the mindset of individual readers as well as about historical forms of information management. Annotated books have for instance been studied to gain inside in the circulation of Copernicus’ revolutionary ideas, but they have also shed light on the way in which an author such as Constantijn Huygens reworked his primary and emotional response to what he read into a rational and intellectual argumentation.
Annotated Books Online enables its users to upload printed books from public and private libraries from around the globe, creating their own collection based on content instead of physical location, an on-line interactive archive of early modern annotated books. The platform enables researchers to collaborate on transcribing and interpreting such annotations. Instead of a traditional textual per-book or per-page approach, Annotated Books Online provides graphical tools to attach relevant information to any specified area on a scanned page. Researchers can upload their own digitized books and collaborate on material provided by others, thereby eliminating the traditional one-directional approach. Results are immediately made available to the general public, bringing the spirit of Wikipedia to the world of early modern books.
While Annotated Books Online is intentionally limited to early modern annotated books, its open-source nature allows it to be adapted for any other domain of knowledge where position-dependent information on digital objects is involved. I will discuss several questions that a project like Annotated Books Online can raise, such as:
- what interaction between libraries and groups of researchers should we envision if more tools like Annotated Books On Line are developed?
- what interaction between the public (in this case even book collectors with special and valuable annotated copies) and researchers should we envision in project with Annotated Books On Line’s open structure. What benefits and downsides should we consider?
- what standards should we follow or develop for projects such as these?
The Problem of Provenance: Can Digital Resources Help?
Abigail Firey
Department of History
University of Kentucky
afire2@uky.edu
Among the most challenging questions medievalists confront when determining a text’s transmission history are difficulties in establishing the date and provenance of each manuscript, in relating provenance to the circumstances or means by which manuscripts or scribes moved from one locale to another, and in using evidence of provenance to analyse the original authorship, impetus for composition, or range of influence to be ascribed to a text. As all manuscript scholars and curators know, the very term “provenance” begets its own uncertainties: it may refer to the place where the text was initially inscribed, or to a library that later held the manuscript and which is the last identifiable site in its history. There are thus a range of strategies for determining provenance: paleographical analysis of script; codicological analysis that relates aspects of the physical artifact to a particular scriptorium; investigation of medieval library catalogues; investigation of the transfer of groups or entire collections of manuscripts from one repository to another, or external reports that illuminate the travels of a text or manuscript. The multiplicity of approaches requires a multiplicity of resources and tools. Beyond the issues attendant upon establishing provenance, however, lie the subsequent issues in tracing the movement of texts and manuscripts, which may be described as a web of provenance problems.
This paper seeks to explore the potential of digital resources and tools to construct an international, large-scale, open access project that helps medievalists both to identify possible provenance and transmission patterns for the texts on which they are working, and also to integrate their information about provenance and transmission into a larger data set. It takes as a test case the model of Carolingian legal texts and manuscripts. These texts are fluid, because the statutes, each about a short paragraph in length and autonomous in content, can easily be added, deleted, or substituted for another; the corpus, however, is enormous and the incentive to transmit them widely was rooted in imperial and ecclesiastical efforts to disseminate a reasonably common set of legal principles and practices. Because so many of them are written in Carolingian minuscule, a script that is simple and often undifferentiated in form, problems in assigning date and provenance can be acute. With these challenges in mind, the paper asks for consideration of the following questions: which partners, and on what scale, need to participate in designing an extensible project that assembles provenance data, provides digital, collaborative workspaces to host paleographic and other investigative research, and creates software for effective visualisation of the patterns of manuscript production and transmission? How should GIS be harnessed to the needs of manuscript scholars? What sort of filters should be designed to allow users to reduce overload in the visualisations and find the sites and routes that most closely match those of the manuscripts and texts they are investigating? How should the project’s design anticipate extension to other areas of textual study? In sum, this paper is intended to elicit ideas for a future project, rather than to present an existing tool or project already in development.
In the beginning was the word: On the syntactical annotation of Medieval Nordic texts
Odd Einar Haugen
University of Bergen
odd.haugen@lle.uib.no
Medieval vernacular manuscripts pose a major problem for any linguistic annotation scheme, whether it is of phonology, morphology or syntax. Unlike e.g. Latin manuscripts, which had a comparatively stable orthography in the Middle Ages, vernacular manuscripts offer a wide orthographic variation. Medieval Nordic manuscripts are no exception; to take just one example, the Old Icelandic adjective dökkr ‘dark’ can be spelt in close to 40 different ways. For this reason, Old Norse texts (i.e. Old Icelandic and Old Norwegian ones) are often rendered in regularised orthography, but by the same token their value as sources of the phonology and morphology of the language is greatly reduced.
In the Medieval Nordic Text Archive, we advise editors to transcribe and encode manuscripts on parallel levels.We have identified three focal levels in the representation of the text; the facsimile level, in which the manuscript is copied character by character (including abbreviation marks), the diplomatic level with a higher degree of abstraction, and the normalised level, in which the orthography is regularised according to standard grammars and dictionaries. Cf. Haugen (2004).
In an annotation scheme, there are alternative ways of reducing the orthographical variation and still keep the transcription close to the primary source. In a morphological annotation, the simplest and fastest way of achieving this is simply to lemmatise the text, i.e. to attach a lemma (a citation form) to each word in the text in accordance with one or more established dictionaries. This means that the word becomes the major unit of the annotated text. Since Medieval Nordic manuscripts are all written in scriptio discontinua, the word division does not pose a major problem, although there are a number of graphical words that the lexicographer would like to either split or unite.
For a syntactic annotation scheme the choice of the word as the primary unit is in one sense unproblematic. In the end, a syntactic analysis of a sentence will ascribe different properties to each word. However, most syntactical analyses group words into phrases. This is a practical challenge for several reasons, not least because Medieval Nordic texts are characterised by a high degree of discontinuous phrases. This means that a syntactical analysis which is word–based, not phrasal, will have a distinct advantage in the annotation. This is the reason why we have decided to adopt dependency grammar in the annotation of Medieval Nordic, specifically in the ongoing Menotec project of annotating Medieval Norwegian (1200–1400). See Mel’čuk (1988) and Nivre (2005) for specifications.
In this talk, I would like to demonstrate how a word-‐based syntactic analysis is a robust way of annotating a Medieval Norwegain text corpus. As it happens, a similar annotation scheme has been (or is being) used for several other older languages, viz. Greek, Latin, Gothic, Armenian, Church Slavonic, Old English, Old French, Old Spanish and Old Portuguese (by the PROIEL, ISWOC and Menotec projects respectively). See the guidelines for these projects by Haug (2010) and Haugen & Øverland (2013).
This means that the Medieval Norwegian corpus will enable syntactical research also on a rather broad comparative level, in addition to specific studies of Old Norwegian. Since the majority of data for Old Norse is based on Old Icelandic, an annotated corpus of Old Norwegian should prove valuable.
Reconfiguring the Scholarly Surround in a Digital Age: the Case of the Scholarly Edition
Eugene W. Lyman
Editor Piers Plowman Electronic Archive
eugene.lyman@gmail.com
Cognitive psychologist David Perkins espouses the view of cognition as a distributed process that takes place at the intersection of individual capacities and a “surround” consisting of an array of assistive entities – tools for thinking – lodged in the physical and social environment in which the individual resides. This paper will ask listeners to consider a “scholarly surround” modeled on the more capacious surround that Perkins references but limited to an enriched subset of the more general “everyday” surround comprised of a web of physical, social, and cultural elements that have evolved in stepwise fashion alongside the corpus of modern scholarship.
My paper addresses the reconfiguration of our shared scholarly surround occasioned by present-day digital technologies by focusing on the scholarly edition as an exemplary proving ground where specific responses to the digital revolution are being explored. In doing so it will draw upon a theoretical framework informed by contemporary cognitive studies and on my own more than decade-long experience producing software aimed at improving our capability to inspect and analyze medieval manuscripts. From the start, my objective has been precisely that implied by this workshop’s title: to create readily useable, “intuitive” tools organized around the task of presenting electronic scholarly editions.
In order to give practical point to my presentation, I will focus on three kinds of challenges that had to be addressed if the software that I was designing was to pass the ease-of-use test that I set for it. The first set of challenges has its origin in the very brief span of visual memory and in the negative consequences that follow when its capacity is overburdened – as it often is digital editions that combine manuscript images with the presentation of edited text. The second challenge that I will address involves harvesting the benefits arising from the mobility that text and image possess in an electronic setting through the dissociation of their format in while storage from that imposed during their visual presentation to readers. This flexibility opens the possibility of fruitful rearrangements of text and/or image that can permit readers to trace hitherto unobserved patterns in each. But the management of that mobility so that readers are presented with effective and clear ways of achieving these rearrangements is by no means a given – it must be designed into the software that mediates a reader’s experience of the edition. The third set of challenges I will address arises when print-based notational formats are carried into an electronic edition’s critical apparatus. The challenge here is to amend the opportunity loss incurred by the old notation’s failure to create an effective means of sorting through the complexity that manuscript relations can attain.
My account of these challenges will blend insights from cognitive theory with others gleaned from praxis and will be accompanied by demonstrations of specific tools that I have developed.
EVT – Edition Visualisation Technology: a simple tool for browsing digital editions
Roberto Rosselli Del Turco
Dipartimento di Studi Umanistici
Università di Torino
roberto.rossellidelturco@unito.it
Raffaele Masotti
Università di Pisa
raffaele.masotti@gmail.com
The TEI (http://www.tei-c.org/) schemas and guidelines have made it possible for many scholars and researchers to encode texts of all kinds for (almost) all kinds of purposes: from simple publishing of documents in PDF form to sophisticated language analysis by means of computational linguistics tools. It is almost paradoxical, however, that this excellent standard is matched by an astounding diversity of publishing tools, which is particularly true when it comes to digital editions, in particular editions including images of manuscripts. This is in part due to the fact that, while there’s still an ongoing discussion about what exactly constitutes a digital edition, available publications have significantly raised users’ expectations: even a simple digital facsimile of a manuscript is usually accompanied by tools such as a magnifying lens or a zoom in/out tool, and if there is a diplomatic transcription (and/or a critical edition) we expect to have some form of image- text linking, hot-spots, a powerful search engine, and so on. The problem is that all of this comes at a cost, and the different needs of scholars, coupled with the constant search for an effective price/result ratio and the locally available technical skills, have a led to a remarkable fragmentation: publishing solutions range from simple HTML pages produced using the TEI style sheets (or the TEI Boilerplate software) to very complex frameworks based on CMS and SQL search engines. Choices are good, except when you are not satisfied with the “simple way”, and the “complex way” is … well, too complex and possibly beyond one’s financial means.
Wouldn’t it be nice if there were a simple, drop-in way to create a digital edition? The TEI Boilerplate software takes this approach exactly: you apply an XSLT style sheet to your already marked-up file(s), and you’re presented with a web-ready document. Unfortunately, this project doesn’t cover the case of an image-based digital edition I presented above, which is why I had to look elsewhere for my own research: the Digital Vercelli Book project aims at producing an online edition of this important manuscript, and has been examining several software tools for this purpose. In the end, we decided to build a software, named EVT (for Edition Visualisation Technology), that would serve the project needs and possibly more: what started as an experiment has grown well beyond that, to the point of being almost usable. EVT is based on the ideal workflow hinted above: you encode your edition, you drop the marked up files in the software directory, and voilà: after applying an XSLT style sheet, your edition is ready to be browsed. The project is nearing an alpha release (v. 0.2.0) on Sourceforge, and already offers all the tools listed above, with the exception of a search engine (expected to land in v. 0.3.0).
(accessed on February 2013).
(accessed on February 2013).
Modern Language Association of America.
The HisDoc Project: Historical Document Analysis, Recognition, and Retrieval
A. Fischer
University of Bern
H. Bunke
University of Bern
M. Baechler
University of Fribourg
R. Ingold
University of Fribourg
rolf.ingold@unifr.ch
N. Naji
University of Neuchatel
J. Savoy
University of Neuchatel
jacques.savoy@unine.ch
The objective of the HisDoc project is to develop automatic generic tools to support historical documents. More precisely, historical manuscripts are automatically transformed from ink on parchment into digital text while keeping human intervention to the least extent possible. The goal is to make the textual content of these manuscripts fully searchable by users and to evaluate the overall quality of the automatic process compared to an error-free version.
It is known that the manuscripts suffer from degradation due to aging factors such as stains, holes, faded writing and ink bleeding (Antonacopoulos & Downton, 2007). Moreover, the identification of the various artifacts, decorated initials and page layouts constitute the first task to be solved in the HisDoc project (Likforman et al. 2007), (Baechler & Ingold, 2011). The automatic text recognition encounters various difficulties such as stitching, additional texts added within marginal spaces or between lines, and the non-uniform handwriting produced by several writers per a single manuscript (Fischer et al., 2009; 2010).
In the last task, the search with older languages (such as Middle High German) requires soft matching to allow orthographical variation (e.g., Parcival, Parcifal, Parzifal). Moreover, we need to take account for the various suffixes added to nouns, adjectives and names to indicate their grammatical case (e.g. Parcival, Parcivale, Parcivals, Parcivalen). Finally the search process must face with imperfect text recognition. Without specific pre-processing, these factors will seriously degrade the search performance (Naji & Savoy, 2011).
Our experiments are mainly based on a well-known medieval epic poem called Parzival, attributed to Wolfram von Eschenbach (first quarter of the thirteenth century). Currently, several versions (with variations) can be found but the St. Gall collegiate library cod. 857 is the one used for experimental evaluation (Fischer et al., 2009). In addition to the fully automatic version, an error-free transcription was created manually and made available by the experts. This error-free version was used to assess the performance levels throughout our experiments.
Based on our new text recognition model, we were able to achieve a word error rate of around 6% with the Parzifal’s manuscript. Similar levels were also obtained with the Saint Gall corpus (medieval Latin manuscript, 9th century). Having less training data (G. Washington corpus, longhand, 18th century, English) the word error rate is higher (around 18%).
For the retrieval task, we evaluate the capability of the search system to retrieve a single line of text based on a user’s request (one to three words). With the Parzival’s corpus and with a dedicated search system taking account for both orthographical and morphological variations, the retrieval degradation was around 5% compared to the error-free version. Using a modern English corpus (printed documents, 20th century, OCR error rate of 5%), the retrieval performance degradation was around 13%. Overall, a high volume of training data (error-free) is key for a successful automatic processing of medieval manuscripts.
Two and more steps leading to a digital multitext edition. Transcription and collation routines used in the Parzival Project
Michael Stolz
Bern University
michael.stolz@germ.unibe.ch
Reinhard Priber
Bern University
The production of digital multitext editions requires a wide range of preparatory steps. In the case of texts transmitted in (medieval) manuscripts, the witnesses have to be transcribed according to encoding rules. The transcriptions then will be collated following certain ideas and concepts on how the transmission process could have developed (phylogenetic analysis can help in this concern). The transcriptions and collations finally have to be transferred to a digital edition that allows the users to explore the characteristics of single witnesses as well as the history of a text, which is delivered in variants and in different versions. A dynamically organized database offering various components and adapted to the needs of diverse user-profiles is nowadays the right tool for this purpose.
The contribution offered to the Huygens workshop will demonstrate the different steps described above in the context of the experiences made in the Parzival Project. The electronic edition of Wolfram’s German Grail novel, written shortly after 1200 and transmitted during several centuries in ca. hundred witnesses (complete manuscripts as well as fragments), started about a decade ago. Over a longer period, transcription rules have been established that consider particular manuscript features as well as the compatibility with international standards such as TEI. For the collation of the manuscripts belonging to different textual versions, an electronic mask that allows the editors to handle a text transmitted in complex variation has been developed.
In the beginning of the project, program packages such as Collate seemed to be the adequate tool for producing an electronic edition right from the transcription up to the final product including collations, variant apparatuses and digital images. In a later period of the project the editors switched to TuStep, a highly sophisticated program, which due to its flexible character fitted in better with their needs. However, by using this tool, the collations concentrate more on the editor’s handwork than they would have to with the semi-automatic, yet imperfect techniques of Collate. The practical demonstrations given in the context of the talk will also include a plea for enhancing the ingenious potential contained in currently obsolescent programs such as Collate and TuStep.
A final part of the paper will demonstrate the concept of the project database that is currently under construction. This tool will enable the users to find their way through a complex textual tradition. They can browse through both single manuscripts and different versions, and they can edit the text in different encodings, both in electronic and printed form.
Pen to Pixel: Bringing Appropriate Technologies to Digital Manuscript Philology
Michael B. Toth
Walters Art Museum
Baltimore, US
mbt@rbtoth.com
Doug Emery
Walters Art Museum
Lynley Herbert
Walters Art Museum
Diane Bockrath
Walters Art Museum
Ariel Tabritha
Walters Art Museum
Digital representation of medieval manuscripts and their key elements – ranging from beautiful illuminations to ancient hidden diagrams and texts – pose significant challenges for the application of appropriate technologies that are efficient and useful to scholars. While users and institutions tend to focus on the technologies and their technical capabilities, one of the most significant elements in development of digital representations of manuscripts is the ability to share and archive digital data for philology, scholarship and preservation research and analysis. Large datasets need to be created and archived with clear storage and access procedures to ensure data integrity and full knowledge of the digital content. Only with common standards, work processes and access can advanced digitization technologies be used for the study of medieval manuscripts in libraries. These are being used in institutions ranging from the ancient library of St. Catherine’s Monastery in the Sinai to the Library of Congress, Walters Art Museum and University of Pennsylvania Library in the United States. Wherever they are located, each is grappling with the challenges of collecting and preserving digital information from medieval manuscripts and codices for future generations.
These libraries use advanced camera systems to capture high-resolution images of manuscripts. Some of these institutions are also conducting spectral imaging studies of manuscripts with advanced collection and digital processing to reveal erased information – such as the earliest copies of Archimedes diagrams and treatises – without damaging the upper layer of text and artwork. These technologies yield large collections of quality digital images for access and study, but the data that becomes the digital counterpart must be effectively stored, managed and preserved to be truly useful for study. Integrating complex sets of digital images and hosting them on the Web for global users poses a complex set of challenges.
Management of large volumes of image datasets, with independent verification and validation of data and metadata, is critical to the successful integration of digitized medieval manuscript data into institutional systems for sharing and access. Medieval manuscript digital storage and archiving is guided by NASA with the Reference Model for an Open Archival Information System (OAIS) developed by the Consultative Committee for Space Data Systems (CCSDS).
OAIS serves as the impetus for the PREMIS (Preservation Metadata: Implementation Strategies) standard for digital data preservation. This model supports an integrated system of receiving, storing, and disseminating data with data sets that are self-documenting and allow for access and discoverability in both near- and long-term time frames by both humans and machines.
With application of globally accepted standards that allow data sharing, we have opportunities to preserve medieval manuscripts in a digital repository for years of study. Medieval manuscripts were preserved on parchment from war, environmental effects and theft for over a thousand years by protecting them in libraries. Now broader access to digital library data, with open licensing and unmediated presentation of the data, is helping to ensure sharing on Internet servers around the globe so the data will not become obsolete on an aging disk or single server system.
Sharing Ancient Wisdoms: Transforming Old Sayings into Linked Data
Charlotte Tupman
King’s College London
charlotte.tupman@kcl.ac.uk
Elvira Wakelnig
University of Vienna
The Sharing Ancient Wisdoms (SAWS) project is funded by HERA (Humanities in the European Research Area) as part of a programme investigating cultural dynamics in Europe, and comprises teams at King’s College London, The Newman Institute, Uppsala, and the University of Vienna. We use digital technologies (TEI XML, RDF) to present, analyse and connect the tradition of wisdom literatures in Greek, Arabic and other languages (Adrados 2001, Gutas 1981). SAWS focuses on gnomologia (or florilegia), manuscripts compiled throughout antiquity and the Middle Ages that collected moral or social advice, and philosophical ideas (Richard 1962).
These manuscripts are collections of extracts of earlier works, in which sayings were often selected, reorganised, modified or reattributed. The genre crossed linguistic barriers, in particular being translated into Arabic, and later into western European languages. The material is interrelated in a variety of ways, an analysis of which can reveal much about the dynamics of the cultures that created and used these texts.
SAWS has three main aspects:
- The encoding and publication of digital editions of a number of these texts;
- The identification, publication and display of the links between the anthologies, their source texts, and recipient texts;
- The building of a framework for scholars outside the project to link their texts to ours and to other relevant resources in the Semantic Web.
We are creating a network of linked information, a collection of marked-up texts and textual excerpts, linked together to allow researchers to represent, identify and analyse the flow of knowledge and transmission of ideas through time and across cultures (Dunn 2012, Hedges 2012).
We will give a live demonstration of our framework for representing these relationships and linking them to related texts using TEI XML and RDF. We will also discuss the tools we are building for visualising, analysing and publishing these texts, and will examine the problems and solutions that we have experienced (academic and technical).
We would particularly like to address and give an example of the way in which we deal with fragments or quotations of texts now lost. Some of our material preserves excerpts of Arabic versions of Greek texts which were composed in the 9th and 10th century and are today no longer extant in their entirety. A comparison with the Greek models allows us to establish the ultimate source texts, but provides no information about the stages of transmission. Digital tools would be ideal to file and arrange excerpts of lost texts from various sources and to examine the clues they give as to the transmission process. This could lead to a partial reconstruction of lost texts and their transmission process, at the very least.
Interaction with other projects and resources is a main incentive of our project, which has become a truly collaborative and interdisciplinary endeavour, so we would very much welcome the opportunity to present and discuss our work at this workshop.
Axes, halberds or foils? Tools to get to grips with the manuscripts of Njál’s saga
Ludger Zeevaert
Háskóli Íslands University, Reykjavík
ludger@zeevaert.de
As the organisers of this workshop state, mediaeval manuscripts are notoriously difficult inhabitants in the digital scholarly ecosystem. An especially notorious specimen is the Old Icelandic Njál‘s saga, which, besides the two Eddas, is regarded as the most important Icelandic literary source from the Middle Ages. It is extant in 60 manuscripts from the 14th to the 19th century, many of them only fragmentary.
Njál‘s saga is the subject of an ongoing research project at the Árni Magnússon Institute in Reykjavík which aims to re-evaluate the textual transmission of the saga and prepare a new edition of the text. In order to accomplish these tasks, an examination of the synchronic and diachronic variation across the manuscripts from a linguistic, literary and philological perspective is being conducted. First of all, this requires a thorough and accurate transcription of the texts to enable access to linguistic and palaeographic traits and peculiarities of every text witness. In addition to this, suitable methods to compare these transcriptions are needed.
The project began with the hope of being able to use existing tools especially designed for the comparison and stemmatological analysis of texts transmitted through a large number of text witnesses. It soon turned out, though, that tailor-made solutions suitable for our purposes are not yet at hand, and, being based in an economically rather challenging environment, the project opted for a low-budget strategy of tool-development. My presentation will deal with the main approaches used in our project and developed with the generous help of the international community of digital humanities scholars.
The presentation will begin with a description of how we have marked up information for linguistic, philological and literary analyses (with an emphasis on linguistics), and the methods currently used to exploit our texts linguistically and philologically. Those methods build essentially on the extraction of selected information from XML-transcriptions, mostly with the help of XSLT and XSL-FO.
Of special interest for this workshop, however, might be a discussion of the general principles of text entry according to the MENOTA-standard and our user-based experiences regarding their compatibility with stemmatological tools and usability for the compilation of digital editions. The latter point is of interest beyond the limits of philological research. The outstanding importance of the Icelandic manuscript collection, which is part of the UNESCO World Heritage list, is unquestioned not only in the Icelandic society, but also internationally (in 2009, the Arnamagnaean collection was listed on the UNESCO World Heritage list). In our opinion, it is necessary to build on this recognition by making the manuscripts available in editions that live up to modern standards. It would be of special interest for us to discuss ideas about how to present the Icelandic manuscripts in their proposed new location, the “Hús íslenskra fræða” in Reykjavík (opening 2016), with regard to the state of the art in digital editing.
Representation of the Tenor of Medieval Charters by Means of Controlled Natural Languages
Aleksandrs Ivanovs
Daugavpils University/Rezekne University, Latvia
aleksandrs.ivanovs@du.lv
Aleksey Varfolomeyev
Petrozavodsk State University, Russian Federation
avarf@petrsu.ru
Due to the progress of Semantic Web technologies, semantic publications of medieval manuscripts (historical records) assume paramount importance (Mirzaee 2005, Ivanovs 2011). Electronic text publications that are provided with additional information layers, which display the sense of the texts, as well as knowledge about the texts in a formalized way (De Waard 2010), provide better facilities for searching for information. Moreover, since formalized knowledge can generate new knowledge, semantic publications can be used as knowledge bases for further research.
However, existing approaches to production of semantic publications are oriented first and foremost to representation of meta-information about the texts as well as some, arbitrary aspects of the tenor of the texts (Ide 2007, Ahonen 2009, Varfolomeyev 2012). Meanwhile, it is desirable that the tenor of medieval manuscripts should be represented fully in order to aggregate their ‘internal’ information within a definite semantic network as well as to link this information with ‘external’ information presented by different ontologies. This might also be useful for an in-depth research as well as for dating and attribution of medieval manuscripts. It seems that in semantic publications the tenor medieval manuscripts can be represented comprehensively by means of controlled natural languages (Fuchs 2010).
The paper discusses some principal problems of representation of the tenor of medieval manuscripts (charters) in semantic publications by means of Attempto Controlled English (ACE, De Coi 2009) which is one of the most expressive and widely spread controlled natural languages.
The case study, which has been conducted in the course of creation of the prototype of the semantic publication that embraces a number of medieval Russian charters, reveals the advantages of ACE: ACE texts can be translated into Discourse Representation Structures (Kamp 1993) that are directly correlated with first-order logic formulas. Furthermore, texts in ACE can be processed using ACE Reasoner (Attempto 2013), which generates new hypotheses on the bases of the facts revealed by a researcher. ACE makes it also possible to record axioms and inference rules. As a result, a great number of facts related to the texts can be entered and processed automatically due to the opportunities offered by ACE. At the same time, new knowledge about medieval manuscripts, namely new facts and hypotheses, can be acquired by means of automatic inference.
Production of a semantic publication of medieval manuscripts on the basis of controlled natural languages poses a number of methodological problems. One of the major problems is applicability of such languages to the purposes of representation of original texts on the Web, since any translation to a certain extent alters the sense of the texts. In this connection, it can be argued that rendering original texts into ACE does not substitute them for ‘surrogates’: ACE texts are linked with diplomatic transcriptions of manuscripts that are represented within the same semantic network, and ACE can be viewed as a mere technology used for the generation of a semantic network.
CATMA: Computer Aided Textual Markup & Analysis
Evelyn Gius
University of Hamburg
evelyn.gius@uni-hamburg.de
Janina Jacke
University of Hamburg
janina.jacke@uni-hamburg.de
Jan Christoph Meister
University of Hamburg
jan-c-meister@uni-hamburg.de
Marco Petris
University of Hamburg
marco-petris@uni-hamburg.de
CATMA is a practical and intuitive tool for literary scholars, students and other parties with an interest in text analysis and literary research. Being implemented as a web application in the newest version, CATMA also facilitates the exchange of analytical results via the internet, which makes collaborative work more comfortable.
CATMA integrates three functional, interactive modules: the Tagger, the Analyzer and the Visualizer. The Tagger module offers an intuitive graphical interface and a wide range of options for the definition of Tags suitable for marking up a text. Due to the use of Feature Structures, CATMA allows for flexibility and still corresponds to relevant XML and TEI standards, enabling tools’ interoperability. Being a Standoff Markup technique, Feature Structures also permit overlapping Markup. The Analyzer module contains different text analytical functions as well as a natural language based Query Builder, allowing the user to execute complex and powerful Queries without having to learn a complicated Query language. The Visualizer module offers the possibility of generating distribution charts of the results of analyses, making the evaluation of results more comfortable.
Within the frameworks of the project heureCLÉA, the CATMA team is aiming to implement further (semi-)automated functions using machine learning processes. The ambition is to enable CATMA to generate automated Markup of time-related phenomena in literary texts up to a certain level of complexity as well as to point out the cases in which automated Markup is impossible due to high complexity or ambiguity.
In a hands-on session, we will demonstrate the possibilities CATMA offers for the analysis of medieval texts.
Revealing textual and manuscript networks using GEPHI
Herman Brinkman
Huygens Institute for the History of the Netherlands
herman.brinkman@huygens.knaw.nl
More often than not medieval miscellanies contain one or more texts that are also transmitted through one or more other manuscripts. Depending on genre, language and other textual or codicological aspects these interrelationships can form intricate to extremely complex networks. Repertories of texts of a certain genre may give a sense of the complexities involved, however, a textual description of such manuscript interdependencies seems like a hard thing to visualise mentally. Given the proper tools, we may visualise a manuscript network, and show not only direct but also indirect connections between manuscripts.
In my paper I will demonstrate a visualisation experiment of a group of 182 manuscripts containing texts in the genre of rhymed prayers in Middle Dutch by using GEPHI, an open source tool that is commonly used for depicting social networks, but which has also been used for literary studies. I will discuss some of the advantages and limitations of this method.
Futhermore I will propose a way in which this tool may be of use in visualising networks between texts instead of manuscripts. Textual relations may occur on many levels. Here I will take parallel lines (i.e. lines that occur verbatim in other texts), a stylistic feature that frequently occurs in rhymed texts in Middle Dutch, as edges between the nodes (which are the texts) of the network in order to show pattern of clustering and compare the results with observations concerning interrelationships made by traditional philology.
The aim is to reveal patterns of clustering that may be indicative of textual cultures and subcultures within a large amount of textst of a certain genre, within a single miscellany or a chosen set of manuscripts. Among other applications this method may be of use in research into questions that involve textual origin or relationship like authorship attribution.
Transcribe Bentham: Crowdsourced Transcription of a Scholarly Edition
Tim Causer
Bentham Project
Faculty of Laws, University College London
t.causer@ucl.ac.uk
The award-winning crowdsourced transcription project, Transcribe Bentham, was launched to the public in September 2010, and recruits volunteers from around the world to transcribe the vast manuscript corpus of the philosopher and reformer, Jeremy Bentham (1748-1832). Bentham is best known as the originator of the ‘panopticon’ prison, and for requesting that his corpse be preserved and put on display (his auto-icon sits in a box at UCL). However, Bentham’s thought is of both great historical importance and contemporary relevance, and he wrote on a wide range of topics including representative democracy, convict transportation, religion, sexual morality, punishment, and much more.
The Bentham Project at UCL was founded in 1959 to produce the new edition of The Collected Works of Jeremy Bentham, based upon his manuscripts and published works. This is no mean task: UCL’s Special Collections holds around 60,000 (c. 30 million words) folios of Bentham manuscripts, and the British Library has another 12,500 folios (c. 6 million words). To date, twenty-nine of a projected seventy volumes of the Collected Works have been published, and about 25,000 folios have been transcribed. The completion of the edition is thus some way off, and Transcribe Bentham intends to increase the pace of this process.
Volunteer transcribers access the material through the ‘Transcription Desk’, a customised MediaWiki developed by the University of London Computer Centre, which incorporates the transcription interface, image viewer, discussion forum, user pages, and other important elements. Volunteers are asked to transcribe the manuscripts and encode their work in TEI-compliant XML, and as of 1 March 2013, participants have transcribed or partially-transcribed 5,146 manuscripts, of which 4,887 (94%) have been accepted by project staff.
The work of volunteers has two main purposes. First, transcripts of sufficient quality will be uploaded to UCL’s free-to-access digital Bentham Papers repository, to widen access, allow for searching, and ensure the long-term digital curation of the material. Second, Transcribe Bentham allows volunteers to contribute to humanities research: transcripts will act as a starting-point for future volumes of The Collected Works of Jeremy Bentham, and as a great many of the manuscripts have not been read since Bentham wrote them, there is scope for exciting new discoveries to be made.
This paper will discuss the development of the Transcription Desk and its technical specifications, the digitisation of the manuscripts, the day-to-day running of the project, and will detail some of the feedback we have received from participants. It will also discuss the ongoing modification and improvement of the Transcription Desk, which is being funded by a grant from the Andrew W. Mellon Foundation. These changes include the introduction of a more flexible image viewer; making it more straightforward to distinguish between transcribed and untranscribed manuscripts; and the introduction of a What-You-See-Is-What-You-Get transcription interface, and allow volunteers to whether they wish to add mark-up manually. The code for the improved Transcription Desk will be made available for others, who wish to crowdsource their own manuscript collections, to use and customise for their own purposes.
eLaborate3: establishing the boundaries
Karina van Dalen-Oskam
Textual Scholarship
Huygens ING
karina.van.dalen@huygens.knaw.nl
Ronald Haentjens Dekker
IT R&D
Huygens ING
ronald.dekker@huygens.knaw.nl
eLaborate is an online work environment in which scholars can prepare a digital transcription and/or edition. They can upload scans of the source, zoom and pan, and transcribe the text in a transcription panel. They can annotate the transcribed text, and categorize the annotations according to their own needs, using an intuitive interface, to name only some of the most important functions of the tool. The main reason to develop eLaborate was to help textual scholars to do the work they are specialized in without having to learn and use XML/TEI. In the ongoing development of the tool (eLaborate1 was started in 2003 and eLaborate3 was released in 2011), we had to find a balance in several ways. How could we create an environment which each scholar could use for his/her own specific edition without presenting them with so many options that they lose their way? How can we reduce the users’s dependency on the developers as much as possible? What criteria can we apply to select or reject requested functionality by the users? What to do with the requests that certainly fall outside the boundaries of the tool? In our presentation, we will give an overview of ten years of working on and in eLaborate, the lessons we learned, and the issues we are currently dealing with. In a hands-on session in the Sandbox of eLaborate, attendants will be able to experience the basics of the tool.
Order and Difference: On the Interoperability of Marked-Up Texts
Gregor Middell
Universität Würzburg
gregor@middell.net
XML-based technologies are ubiquitous in the domain of encoding and processing electronic texts for the humanities. Besides XML’s often cited advantages of being a simple, human-readable, yet generally usable markup language with broad industry support, it is also thanks to features unrelated to its widely recognized syntax that this standard dominates the text-oriented realm of Digital Humanities today. Particularly its tree-oriented processing model and its schema support, the latter being mostly based on context-free grammars, allow for essential functionality and ease-of-use in scenarios like data transformation, query facilities and input support. It is for these aspects which relate to XML’s underlying data model, that we appreciate this language as an “easy tool” for texts.
At the same time there have been numerous publications on the shortcomings of XML when applied to the modelling of “difficult texts”. Often subsumed under the catch phrase of “the overlap problem”, many critics emphasize the inability of a tree-oriented data model to cope with the inherent complexity of natural language texts. In contrast, its advocates point to vast improvements over prior standards (e.g. in terms of sustainability) and while they might accede to the theoretical argument, the practical implications are assumed to vanish when approached from a pragmatic angle. This latter view is amplified by the generally experienced empowerment of scholars engaged in XML-based text encoding, as embedded markup is immediately available together with the text and not hidden in a “black box”, for example a word processor.
I would like to present a DH tool builder’s perspective on this debate. In order to build reusable, interoperable tools for DH scholars, those tools do not only have to cope with a particular markup order imposed by a particular scholar on a text while encoding it, but they have to account for multiple such orders and their differences, be they grounded in the interpretative nature of scholarly practice or in differing agendas towards the use of an electronic text. In comparing XML’s tree-oriented to an alternative, range-oriented model of marked-up texts and in focussing on the usability and interoperability of tools built on those models, pros and cons of each model will be laid out. To support this comparison, I will refer to results from prototyping alternative implementations gathered during developer meetings of the Interedition initiative.